













fastdup: One Year Strong and Still Going!
Can you believe it? It’s been a year since we launched fastdup — a free tool for image & video data analysis.



Can you believe it? It’s been a year since we launched fastdup — a free tool for image & video data analysis.
Not only that, one year into running the company Visual Layer, we recently raised $7.5M to help enterprises with massive visual datasets!!
This funding marks a significant milestone in our journey and brings us one step closer to achieving our vision of revolutionizing the way we interact with visual data. — Amir Alush, co-founder
We’re featured in Techcrunch on our journey to getting where we are today.

The reason users like fastdup is that it is easy to use, scalable and accurate for a large variety of datasets. We believe the problem is completely unsolved, especially in the billion images and videos regime. — Danny Bickson, co-founder.
What is fastdup?
If you’re unfamiliar you might be wondering what’s fastdup?
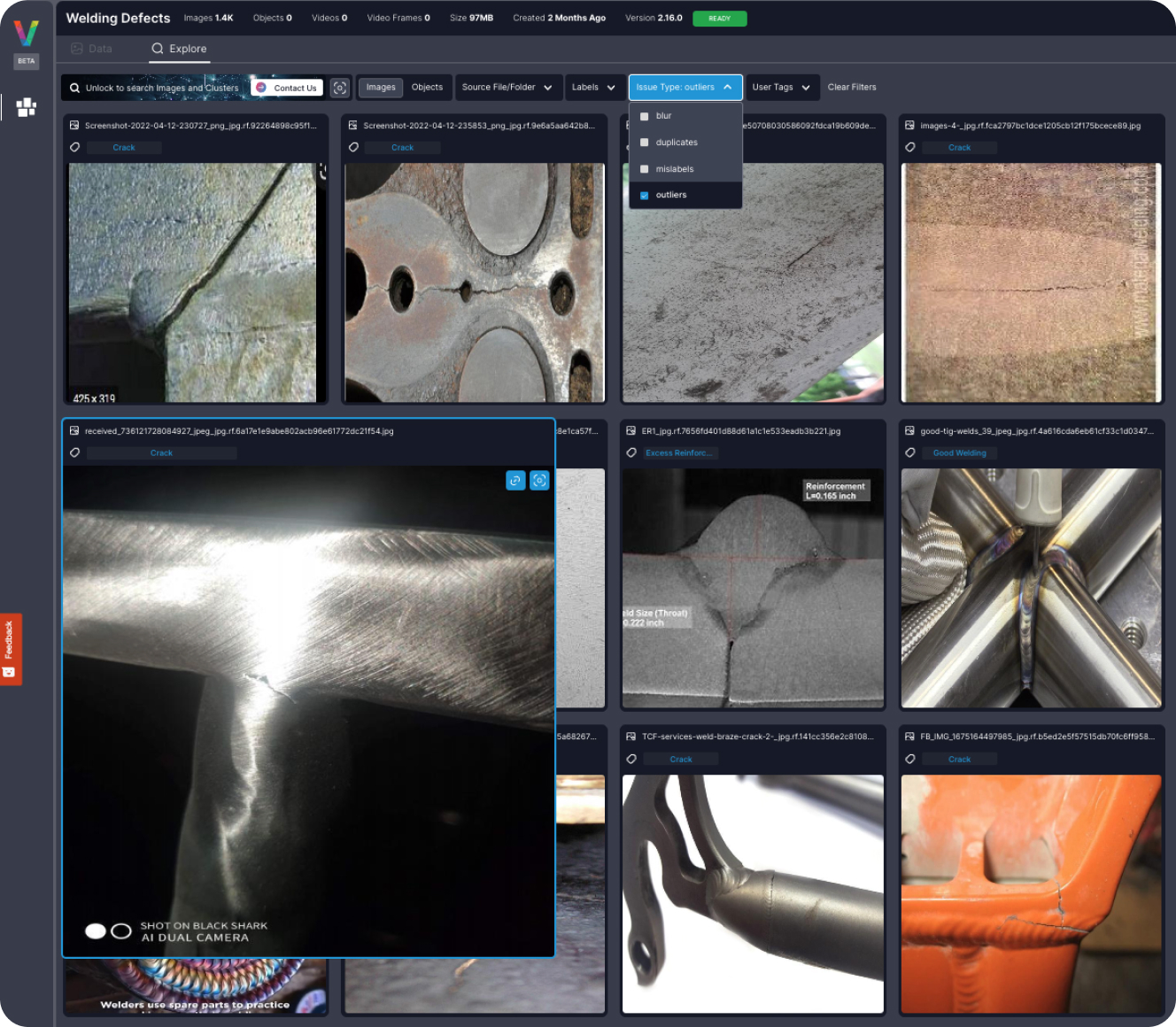
fastdup is a tool that can analyze your computer vision dataset in an unsupervised way.
With fastdup, you can find common issues in your computer vision dataset such as:
1. Duplicates / near-duplicates.
2. Anomalies.
3. Wrong labels.
4. Corrupted images.
5. Blurry images.
6. Overly dark / bright images.

These issues are quite common in large computer vision datasets and it’s an issue that’s largely ignored by most. fastdup works on both labeled and unlabeled datasets. So we got you covered.
In a recent discovery, we find that even widely used computer vision datasets such as ImageNet and LAION have problems with duplicates, broken images, and wrong labels.

These are some of the issues that fastdup addresses. One of the standout features of fastdup is its incredible performance.
Guess what? You don’t even need a GPU to run it! fastdup runs efficiently on a CPUs even on a lightweight 2-core Google Colab instance!
fastdup’s highly efficient graph engine can handle up to 400M images on a single CPU machine.
All you need to get started is 3 lines of code:

In fastdup version 1.0 we’ve made it easier for anyone to get started. Here’s the TLDR:
- Clean & simple API: The new API is simpler to use
- Native Windows support: Windows now has first-class, full feature support in fastdup.
- Amazing documentation: New and improved fastdup documentation.
- Sleek galleries: New and improved galleries to get a better view of your data.
- Extensive labels support : Improved support for handling image and bounding box labels.
- Additional image formats support: Apple’s HEIC+HEIF, 16 bit grayscale TIFF.
- Support for Python 3.10.
- Fully back compatible to old API.
More in our GitHub repo — https://github.com/visual-layer/fastdup
Wrapping Up
All in all, we couldn’t be more grateful and thrilled for such a wild ride over the past year.
None of this would have been possible without the incredible support and contributions from our amazing community. Your feedback, bug reports, and feature suggestions have helped shape fastdup into the robust tool it is today.
Thank you for being part of this journey!
If fastdup had made your life easier in any way over the past year, please help us spread the word and share your experience with other users. On behalf of the fastdup team we’d like to thank you for helping us be where we are today.
Here’s to an incredible year with fastdup and many more to come!

Introduction to Image Captioning
h2
h3
Image Captioning is the process of using a deep learning model to describe the content of an image. Most captioning architectures use an encoder-decoder framework, where a convolutional neural network (CNN) encodes the visual features of an image, and a recurrent neural network (RNN) decodes the features into a descriptive text sequence.
VQA
Visual Question Answering (VQA) is the process of asking a question about the contents of an image, and outputting an answer. VQA uses similar architectures to image captioning, except that a text input is also encoded into the same vector space as the image input.
codeImage captioning and VQA are used in a wide array of applications:
- point
- point
- point
Why Captioning With fastdup?
Image captioning can be a computationally-expensive task, requiring many processor hours to conduct. Recent experiments have shown that the free fastdup tool can be used to reduce dataset size without losing training accuracy. By generating captions and VQAs with fastdup, you can save expensive compute hours by filtering out duplicate data and unnecessary inputs.
quote
Getting Started With Captioning in fastdup
To start generating captions with fastdup, you’ll first need to install and import fastdup in your computing environment.
Processor Selection and Batching
The captioning method in fastdup enables you to select either a GPU or CPU for computation, and decide your preferred batch size. By default, CPU computation is selected, and batch sizes are set to 8. For GPUs with high-RAM (40GB), a batch size of 256 will enable captioning in under 0.05 seconds per image.
To select a model, processing device, and batch size, the following syntax is used. If no parameters are entered, the fd.caption() method will default to ViT-GPT2, CPU processing, and a batch size of 8.
“The captioning method in fastdup enables you to select either a GPU or CPU for computation, and decide your preferred batch size. By default, CPU computation is selected, and batch sizes are set to 8. For GPUs with high-RAM (40GB), a batch size of 256 will enable captioning in under 0.05 seconds per image.”
Dean Scontras, AVP, Public Sector, Wiz
FedRAMP is a government-wide program that provides a standardized approach to security in the cloud, helping government agencies accelerate cloud adoption with a common security framework. Achieving a FedRAMP Moderate authorization means Wiz has gone under rigorous internal and external security assessment to show it meets the security standards of the Federal Government and complies with required controls from the National Institute of Standards and Technology (NIST) Special Publication 800-53.
Image captioning and VQA are used in a wide array of applications:
- ⚡ Quickstart: Learn how to install fastdup, load a dataset, and analyze it for potential issues such as duplicates/near-duplicates, broken images, outliers, dark/bright/blurry images, and view visually similar image clusters. If you’re new, start here!
- 🧹 Clean Image Folder: Learn how to analyze and clean a folder of images from potential issues and export a list of problematic files for further action. If you have an unorganized folder of images, this is a good place to start.
- 🖼 Analyze Image Classification Dataset: Learn how to load a labeled image classification dataset and analyze for potential issues. If you have labeled ImageNet-style folder structure, have a go!
- 🎁 Analyze Object Detection Dataset: Learn how to load bounding box annotations for object detection and analyze for potential issues. If you have a COCO-style labeled object detection dataset, give this example a try.
.png)













