✅ Motivation
As a data scientist, you might be tempted to jump into modeling as soon as you can. I mean, that’s the fun part, right?
But trust me, if you skip straight to modeling without taking the time to really understand the problem and analyze the data, you’re setting yourself up for failure.
I’ve been there.
You might feel like a superstar, but you’ll have with a model that doesn’t work 🤦♂️.

But how do we even begin inspecting large datasets of images effectively and efficiently? And can we really do it on a local computer quickly, for free?
Sounds too good to be true eh?
It’s not, with 👇
⚡ Fastdup
Fastdup is a tool that let us gain insights from a large image/video collection. You can manage, clean, and curate your images at scale on your local machine with a single CPU. It’s incredibly easy to use and highly efficient.
At first, I was skeptical. How could a single tool handle my data cleaning and curation needs on a single CPU machine, especially if the dataset is huge? But I was curious, so I decided to give it a try.
And I have to say, I was pleasantly surprised.
Fastdup lets me clean my visual data with ease, freeing up valuable resources and time.
Here are some superpowers you get with Fastdup. It lets you identify:

In short, Fastdup is 👇
- Unsupervised: fits any visual dataset.
- Scalable: handles 400M images on a single machine.
- Efficient: works on CPU (even on Google Colab with only 2 CPU cores!).
- Low Cost: can process 12M images on a $1 cloud machine budget.
The best part? Fastdup is free.
It’s easy to get started and use. The authors of Fastdup even used it to uncover over 1.2M duplicates and 104K data train/validation leaks in the ImageNet-21K dataset here.
⚡ By the end of this post, you will learn how to:
- Install Fastdup and run it on your local machine.
- Find duplicates and anomalies in your dataset.
- Identify wrong/confusing labels in your dataset.
- Uncover data leaks in your dataset.
📝 NOTE: All codes used in the post are on my Github repo. Alternatively, you can run this example in Colab.
If that looks interesting, let’s dive in.
📖 Installation
To start, run:
pip install fastdupFeel free to use the latest version available. I’m running fastdup==0.189 for this post.
🖼 Dataset
I will be using an openly available image classification dataset from Intel. The dataset contains 25,000 images (150 x 150 pixels) of natural scenes from around the world in 6 categories:
buildingsforestglaciermountainseatree

I encourage you to pick a dataset of your choice in running this example. You can find some inspiration here.
🏋️♀️ Fastdup in Action: Discovering Data Issues
Next, download the data locally and organize them in a folder structure. Here’s the structure I have on my computer.

Description of folders:
➡ data/ – Folder to store all datasets.
➡ report/ – Directory to save the output generated by Fastdup.
📝 NOTE: For simplicity, I’ve also included the datasets in my Github repo.
To start checking through the images, create a Jupyter notebook and run:
import fastdup
fastdup.run(input_dir='scene_classification/data/train_set/',
work_dir="scene_classification/report/train/")Parameters for the run method:
➡input_dir - Path to the folder containing images. In this post, we are checking the training dataset.
➡work_dir - Optional. Path to save the outputs from the run. If not specified, the output will be saved to the current directory.
📝 NOTE: More info on other parameters here.
Fastdup will run through all images in the folder to check for issues. How long it takes depends on how powerful is your CPU. On my machine, with an Intel Core™ i9–11900 it takes under 1 minute to check through (approx. 25,000) images in the folder 🤯.
Once complete, you’ll find a bunch of output files in the work_dir folder. We can now visualize them accordingly.
The upcoming sections show how you can visualize duplicates, anomalies, confusing labels and data leakage. Read on.
🧑🤝🧑 Duplicates
First, let’s see if there are duplicates in the train_set. Let's load the file and visualize them with:
from IPython.display import HTML
fastdup.create_duplicates_gallery(similarity_file='scene_classification/report/train/similarity.csv'
save_path='scene_classification/report/train/',
num_images=5)
HTML('scene_classification/report/train/similarity.html')Parameters for create_duplicates_gallery method:
➡ similarity_file - A .csv file with the computer similarity generated by the run method.
➡ save_path - Path to save the visualization. Defaults './'.
➡ num_images - The max number of images to display. Defaults to 50. For brevity, I've set it to 5.
📝 NOTE: More info on other parameters here.
You’d see something like the following 👇

We can already spot a few issues in the train_set:
➡ On row 1, note that 19255.jpg and 7872.jpg are duplicates of the same class. We know this by the Distance value of 1.0. You can also see that they are exactly the same side-by-side. The same with row 2.
➡ On row 0, images 9769.jpg and 7293.jpg are exact copies but they exist in both the buildings and street folders! The same can be seen on row 3 and row 4. These are duplicate images but labeled as different classes and will end up confusing your model!
For brevity, I’ve only shown 5 rows, if you run the code increasing num_images, you’d find more!
Duplicate images do not provide value to your model, they take up hard drive space and increase your training time. Eliminating these images improves your model performance, and reduces cloud billing costs for training and storage.
Plus, you save valuable time (and sleepless nights 🤷♂️) to train and troubleshoot your models down the pipeline.
You can choose to remove the images by hand (e.g. going through them one by one and hitting the delete key on your keyboard.) There are cases you might want to do so. But Fastdup also provides a convenient method to remove them programmatically.
The following code will delete all duplicate images from your folder. I recommend setting dry_run=True to see which files will be deleted.
📝 NOTE: Checkout the Fastdup documentation to learn more about the parameters you can tweak.
top_components = fastdup.find_top_components(work_dir="scene_classification_clean/report/")
fastdup.delete_components(top_components, dry_run=False)In Fastdup, a component is a cluster of similar images. The snippet above removes duplicates of the same images (from the top cluster) ensuring you only have one copy of the image in your dataset.
That’s how easy it is to find duplicate images and remove them from your dataset! Let’s see if we can find more issues.
🦄 Anomalies
Similar to duplicates, it’s easy to visualize anomalies in your dataset:
fastdup.create_outliers_gallery(outliers_file='scene_classification/report/train/outliers.csv',
save_path='scene_classification/report/train/',
num_images=5)
HTML('scene_classification/report/train/outliers.html')You’d see something like the following 👇

What do we find here?
➡ Image 12723.jpg in the top row is labeled as glacier, but it doesn’t look like one to me.
➡ Image 5610.jpg doesn’t look like a forest.
📝 NOTE: Run the code snippet and increase the num_images parameter to see more anomalies. Also, repeat this with valid_set and see if there are more.
All the other images above don’t look too convincing to me either. I guess you can evaluate the rest if they belong to the right classes as labeled. Now let’s see how we can programmatically remove them.
WARNING: The following code will delete all outliers from your folder. I recommend setting dry_run=True to see which files will be deleted.
📝 NOTE: Check out the Fastdup documentation to learn more about the function parameters.
fastdup.delete_or_retag_stats_outliers(stats_file="scene_classification_clean/report/outliers.csv",
metric='distance', filename_col='from',
lower_threshold=0.6, dry_run=False)The above command removes all images with the distance value of 0.6 or below.
What value you pick for the lower_threshold will depend on the dataset. In this example, I notice that as distance go higher than 0.6, the images look less like outliers.
This isn’t a foolproof solution, but it should remove the bulk of anomalies present in your dataset.
💆 Wrong or Confusing Labels
One of my favorite capabilities of Fastdup is finding wrong or confusing labels. Similar to previous sections, we can simply run:
df = fastdup.create_similarity_gallery(similarity_file="scene_classification/report/train/similarity.csv",
save_path="scene_classification/report/train/",
get_label_func=lambda x: x.split('/')[-2],
num_images=5, max_width=180, slice='label_score',
descending=False)
HTML('./scene_classification/report/train/topk_similarity.html')In case the dataset is labeled, you can specify the label using the function get_label_func.
📝 NOTE: Check out the Fastdup documentation for the parameters description.
You’d see something like 👇

Under the hood, Fastdup finds images that are similar to one another at the embedding level but are assigned different labels.
A score metric is computed to reflect how similar the query image to the most similar images in terms of class label.
A high score means the query image looks similar to other images in the same class. Conversely, a low score indicates the query image is similar to images from other classes.
What can we see in the table above?
➡ On the top row, we find that 3279.jpg is labeled forest but looks very similar to mountains.
➡ On the remaining rows, we see confusing labels between glacier and mountains.
It is important to address these confusing labels because if the training data contains confusing or incorrect labels, it can negatively impact the performance of the model.
TIP: You can repeat the steps to find duplicates, anomalies, and problematic labels for the valid_set and test_set. To do so, you’d have to call the run method again specifying the appropriate dataset folders.
Using Fastdup we can delete or retag these images.
WARNING: The following code will delete all images with wrong labels from your folder. I recommend setting dry_run=True to see which files will be deleted.
📝 NOTE: Checkout the Fastdup documentation to learn more about the parameters.
fastdup.delete_or_retag_stats_outliers(stats_file=df,
metric='score',
filename_col='from',
lower_threshold=51,
dry_run=False)Parameters for delete_or_retag_stats_outliers:
stats_file– The outputDataFramefromcreate_similarity_gallerymethod.lower_threshold– The lower threshold value at which the images are deleted. In the above snippet, anything lower than a score of51gets deleted. The score is in the range 0-100 where 100 means this image is similar only to images from the same class label. A score 0 means this image is only similar to images from other class labels.
📝 NOTE: Checkout the Fastdup documentation to learn more about the parameters.
🚰 Data Leakage
In the Duplicates section above, we tried finding duplicates within the train_set. We found a few duplicate images within the same folder.
In this section, we check for duplicate images that exist in the train and validation dataset. Technically, this should not happen. But let’s find out.
We’d have to call the run method again and specify an additional parameter test_dir.
import fastdup
fastdup.run(input_dir='scene_classification/data/train_set/',
work_dir="scene_classification/report/train_test/",
test_dir='scene_classification/data/valid_set/')fastdup.create_duplicates_gallery(similarity_file='scene_classification/report/train_test/similarity.csv',
save_path='scene_classification/report/train_test/', num_images=5)
HTML('scene_classification/report/train_test/similarity.html')NOTE: Parameters for the in run method:
- The
input_dirandtest_dirpoint to different locations. - The
test_dirparameter should point tovalid_setortest_setfolder.
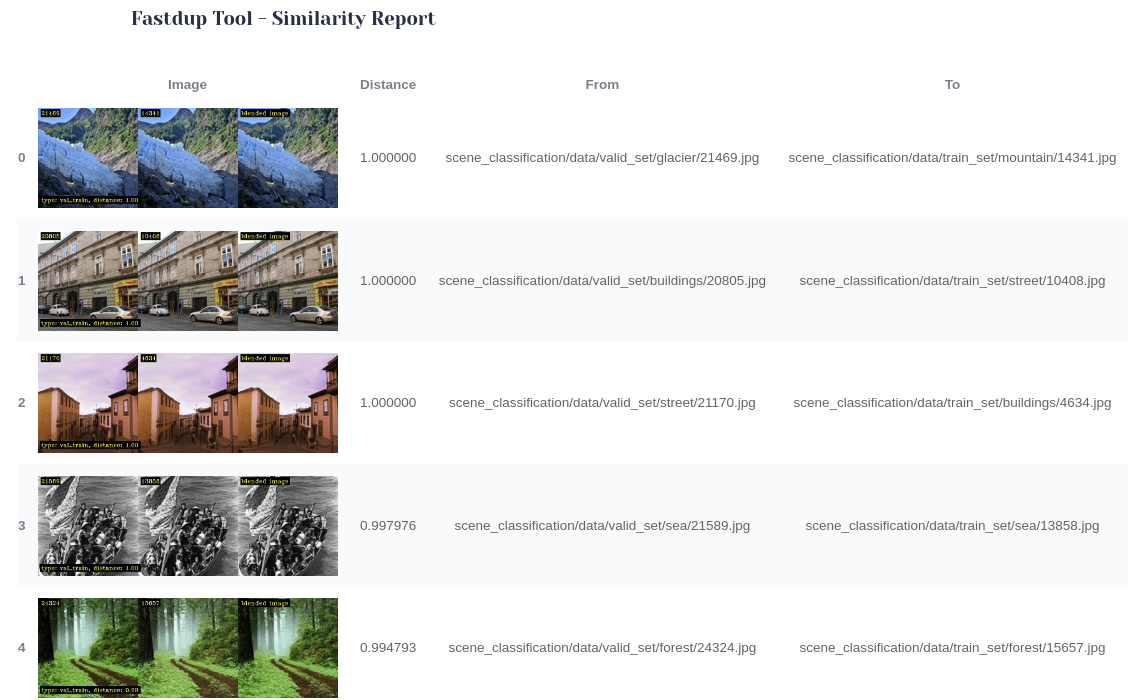
Note the From and To columns above now point valid_set and train_set.
From the table above, we find the following issues:
- Duplicate images in different dataset — On the top row,
21469.jpgand14341.jpgare duplicates but they exist intrain_setandvalid_setrespectively. - Duplicate images with different labels — On the top row,
21469.jpgis labeled asglacierin thevalid_setandmountainin thetrain_set.
This is bad news. We just uncovered a train-validation data leakage!
This is a common reason a model performs all too well during training and fails in production because the model might just memorize the training set without generalizing to unseen data. It’s important to make sure the training and validation sets do not contain duplicates!
Spending time crafting your validation set takes a little effort, but will pay off well in the future. Rachel Thomas from Fastai wrote a good piece on how to craft a good validation set.
You can remove the duplicate images using the delete_components method as shown in the Duplicates section.
🙏 Comments & Feedback
That’s a wrap!
In this post I’ve shown you how to:
- Install Fastdup and run it on your local machine.
- Find duplicates and anomalies in your dataset.
- Identify wrong/confusing labels in your dataset.
- Uncover data leaks in your dataset.
By using Fastdup and cleaning your dataset, you saved yourself:
- Unnecessary labeling cost.
- Long computation/training time.
- Headaches from debugging model predictions due to problems in data.
I believe Fastdup is one of the easiest tools to get started for data cleaning. It’s a low-hanging fruit and ought to be in your toolkit if you’re working with image datasets.
If you’re interested to learn more, I’ve trained a deep learning classification model on the clean version of the data using Fastai. View the training notebook here. The accuracy on the validation set is approximately 94.9% — comparable to the winning solutions of the competition (96.48% with ensembling).
I hope you’ve enjoyed and learned a thing or two from this blog post. If you have any questions, comments, or feedback, please leave them on the following Twitter/LinkedIn post or drop me a message.