













Discover fastdup Advanced Features: Now Available for Free!
New and exciting features to curate your computer vision datasets.



Over the past few months, we’ve been hard at work testing out our beta features, refining their performance, and ensuring they’re ready for prime time.
📣 Today we’re excited to announce all advanced features are out from beta testing and are now available to the public, completely free of charge! To access, head to fastdup GitHub repo.
Here’s a video in a nutshell.
About fastdup
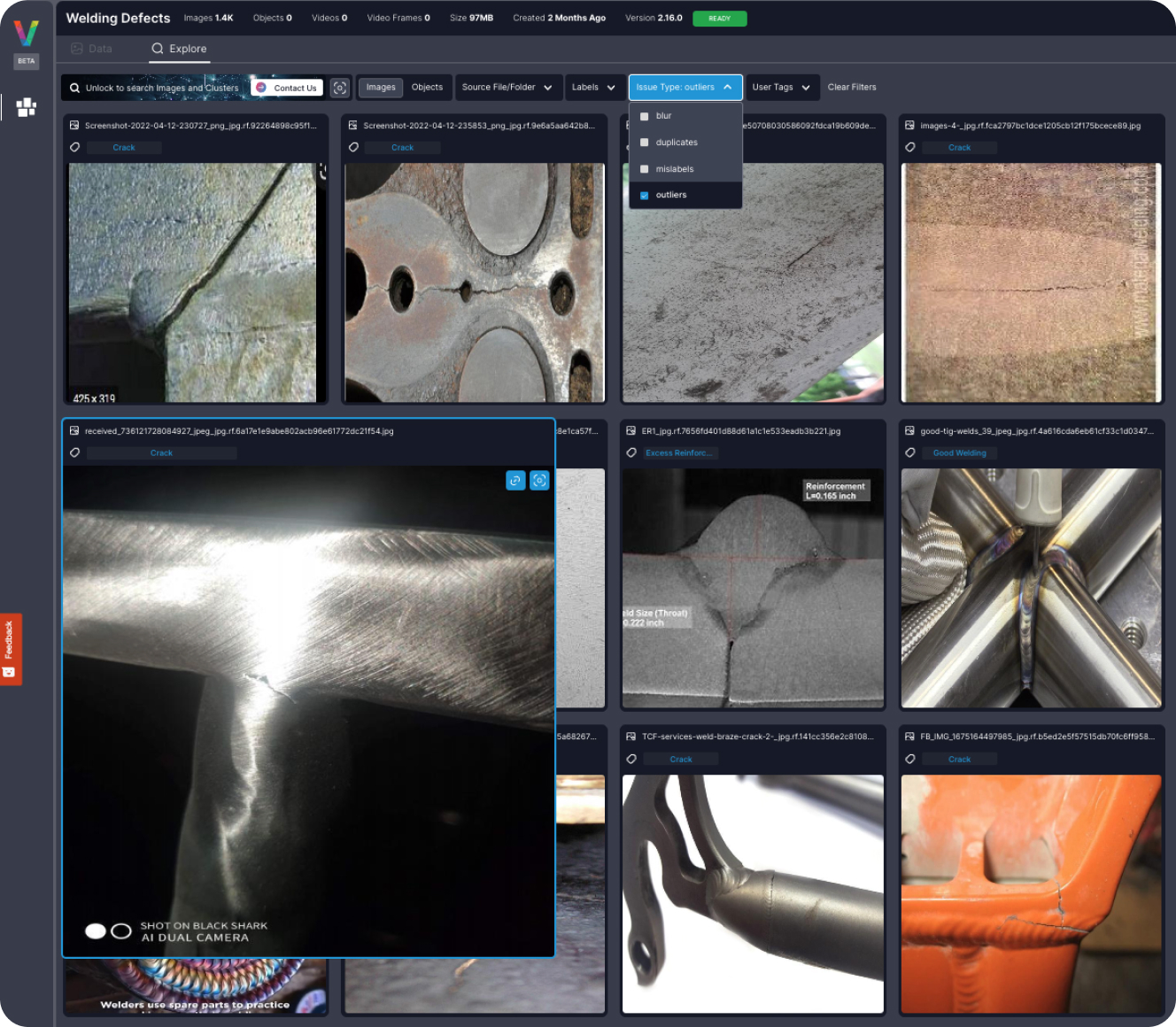
If you’re new, fastdup is an unsupervised and free tool for image and video data analysis.
Over the past year, fastdup has amassed over 247,000 downloads on PyPI and has been used to analyze over 50 billion images in total. This makes fastdup one of the fastest-growing computer vision dataset analysis tools.

If you’d like to try it out yourself head over to fastdup GitHub repo to get started.
Overview of Advanced Features
Today we are releasing many exciting new features that passed our internal beta testing phase.
We categorize these features into 4 sub-categories namely:
- Hugging Face Datasets Support.
- Data Enrichment.
- Embeddings.
- Visual Search.
Hugging Face Datasets Support
Hugging Face Datasets is one of the most widely used libraries to access and share computer vision, audio, and NLP datasets. You can easily load any of the 46,385 datasets (as of July 2023) with just a single line of code.
But what if you’d like to analyze the dataset for issues like duplicates, outliers, or other quality issues?
Now you can easily do that with fastdup.

We loaded the tiny-imagenet dataset from Hugging Face to show how easy it is and analyzed it for issues.
View the notebook on nbviewer or run it yourself on Google Colab.
Data Enrichment
Computer vision datasets are notoriously tricky to analyze. This is when data enrichment plays a role in enhancing the understanding of the images.
With fastdup’s new features, you can enrich your computer vision datasets by adding captions to your image using the BLIP model, detecting visible texts on your images with PaddleOCR, detecting if there are human faces present in the dataset, and detecting if there are objects from the COCO dataset using a pre-trained YOLOv5 model.

By enhancing these images with additional information we can improve the search and retrieval capabilities for images in the dataset. For example with captions, we can easily find relevant images using text queries.
Links to the notebooks are as follows:
- Face Detection in Videos — nbviewer, Google Colab.
- Object Detection in Videos — nbviewer, Google Colab.
- Optical Character Recognition — nbviewer, Google Colab.
- Captioning with BLIP — nbviewer, Google Colab.
Embeddings
Another strategy to enhance search capabilities for image datasets is to use embeddings. Embeddings refer to the vector representation of images that capture their semantic and contextual information.
Using fastdup’s new features you can extract feature vectors of your dataset using the latest DINOv2 model, or any model you prefer. On top of that, you can also use fastdup to read feature vectors and use them for further processing.

Links to the notebooks are as follows:
- DINOv2 Embeddings — nbviewer, Google Colab.
- Use Your Own Feature Vectors — nbviewer, Google Colab.
Visual Search
Finally, we are also happy to release one of the most requested features — large-scale visual search. You can now search through large datasets for similar-looking images using fastdup, on a CPU.

In our example notebook, we searched through the Shopee Price Match Dataset with 32,418 images for similar images in seconds.
View the notebook on nbviewer or run it yourself on Google Colab.
Community and Support
We’re incredibly grateful for our community. Your feedback and contributions have been instrumental in shaping these advanced features.
If you have any questions, feedback or need help, don’t hesitate to reach out via Slack, GitHub, or our discussion forum.
We are also present on LinkedIn, Twitter, or YouTube.
We’re excited to see how you’ll utilize these new features in your projects. Thank you and happy data exploring!


Introduction to Image Captioning
h2
h3
Image Captioning is the process of using a deep learning model to describe the content of an image. Most captioning architectures use an encoder-decoder framework, where a convolutional neural network (CNN) encodes the visual features of an image, and a recurrent neural network (RNN) decodes the features into a descriptive text sequence.
VQA
Visual Question Answering (VQA) is the process of asking a question about the contents of an image, and outputting an answer. VQA uses similar architectures to image captioning, except that a text input is also encoded into the same vector space as the image input.
codeImage captioning and VQA are used in a wide array of applications:
- point
- point
- point
Why Captioning With fastdup?
Image captioning can be a computationally-expensive task, requiring many processor hours to conduct. Recent experiments have shown that the free fastdup tool can be used to reduce dataset size without losing training accuracy. By generating captions and VQAs with fastdup, you can save expensive compute hours by filtering out duplicate data and unnecessary inputs.
quote
Getting Started With Captioning in fastdup
To start generating captions with fastdup, you’ll first need to install and import fastdup in your computing environment.
Processor Selection and Batching
The captioning method in fastdup enables you to select either a GPU or CPU for computation, and decide your preferred batch size. By default, CPU computation is selected, and batch sizes are set to 8. For GPUs with high-RAM (40GB), a batch size of 256 will enable captioning in under 0.05 seconds per image.
To select a model, processing device, and batch size, the following syntax is used. If no parameters are entered, the fd.caption() method will default to ViT-GPT2, CPU processing, and a batch size of 8.
“The captioning method in fastdup enables you to select either a GPU or CPU for computation, and decide your preferred batch size. By default, CPU computation is selected, and batch sizes are set to 8. For GPUs with high-RAM (40GB), a batch size of 256 will enable captioning in under 0.05 seconds per image.”
Dean Scontras, AVP, Public Sector, Wiz
FedRAMP is a government-wide program that provides a standardized approach to security in the cloud, helping government agencies accelerate cloud adoption with a common security framework. Achieving a FedRAMP Moderate authorization means Wiz has gone under rigorous internal and external security assessment to show it meets the security standards of the Federal Government and complies with required controls from the National Institute of Standards and Technology (NIST) Special Publication 800-53.
Image captioning and VQA are used in a wide array of applications:
- ⚡ Quickstart: Learn how to install fastdup, load a dataset, and analyze it for potential issues such as duplicates/near-duplicates, broken images, outliers, dark/bright/blurry images, and view visually similar image clusters. If you’re new, start here!
- 🧹 Clean Image Folder: Learn how to analyze and clean a folder of images from potential issues and export a list of problematic files for further action. If you have an unorganized folder of images, this is a good place to start.
- 🖼 Analyze Image Classification Dataset: Learn how to load a labeled image classification dataset and analyze for potential issues. If you have labeled ImageNet-style folder structure, have a go!
- 🎁 Analyze Object Detection Dataset: Learn how to load bounding box annotations for object detection and analyze for potential issues. If you have a COCO-style labeled object detection dataset, give this example a try.
.png)













